C++ is full of weird features, quirks, and historical artefacts. This is in part due to its aim to have classic C code be valid under the C++ standard from day one. It is also due to the fact that C++ was first published in 1985, and has naturally been filled with all sorts of features, good and bad, over the past 40+ years.
As someone interested in programming language design, I’ve taken an interest in some of these features, eager to see just how hilariously difficult to read C++ code can be.
In this article, I intend to showcase some of these features in action, and so I present the following:
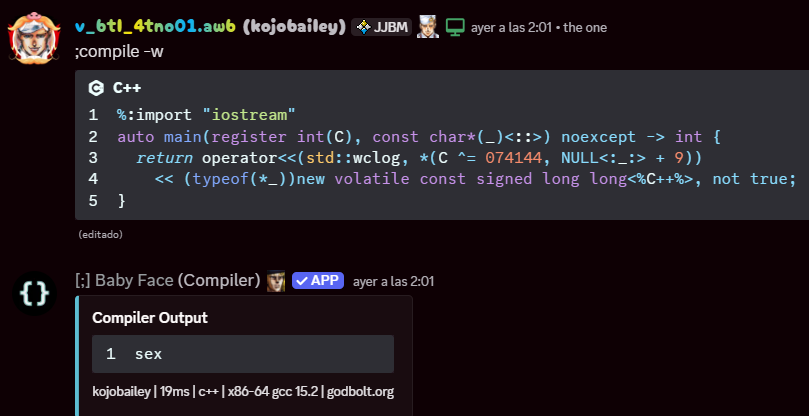
%:import "bits/stdc++.h"
auto main(register int(C), const char*(_)<::>) noexcept -> int {
return operator<<(std::wclog, *(C ^= 074144, NULL<:_:> + 9))
<< (typeof(*_))new volatile const signed long long<%C++%>, not true;
}
I wrote this code while playing around with compiler.gg which uses Godbolt’s Compiler Explorer. It is intended to be compiled in that environment, so if you want to test it yourself, do so via this link with the “x86-64 gcc 15.2” compiler option.
Now, what this code does is simple: It outputs “sex” to the console.
How it goes about it… is less simple, and is what I will attempt to explain in the rest of this article! As I do so though, I invite you to also try and figure things out yourself to test your understanding of C and C++!
Digraphs
https://en.cppreference.com/w/cpp/language/operator_alternative.html
Right away, we are met with this strange %: pair of symbols, and similar symbols like <: :> and <% %> can be seen later in the code as well.
Such symbols are called digraphs - as in “double symbol” - and act as alternative ways to write common symbols for keyboards/systems that do not support ASCII. In particular, this is to comply with the ISO 646 7-bit character set, which lacks common symbols that you may be familiar with as a programmer.
C’s digraphs include:
%:=#<:=[:>=]<%={%>=}
Furthermore, rather than use a digraph for the not operator, !, C includes the not keyword, which can be see towards the end of this code in not true.
Replacing all these alternative representations with their “normal” ASCII counterparts already helps to make the code a lot more readable:
#import "bits/stdc++.h"
auto main(register int(C), const char*(_)[]) noexcept -> int {
return operator<<(std::wclog, *(C ^= 074144, NULL[_] + 9))
<< (typeof(*_))new volatile const signed long long{C++}, !true;
}
Bonus: Trigraphs
C++ also used to support trigraphs up until C++17. These functioned similar to digraphs, except were parsed before both comments and string literals, leading to some funky situations such as "Enter date ??/??/??" becoming "Enter date \\??", hence their eventual removal.
Some of these trigraphs were:
??<={??>=}??(=[??)=]??==#??/=\
That being said, GCC does still include trigraphs as an opt-in feature via the -trigraphs flag - and I must admit, I’m quite tempted to use them for stylised includes.
??=include<stdio.h>
#import
https://gcc.gnu.org/onlinedocs/cpp/Alternatives-to-Wrapper-_0023ifndef.html
Those who have been keeping up with modern C++ should recognise the import keyword, used to import modules as an alternative to classic header includes.
However, #import is not to be confused with this, and goes way back to the 80s/90s when GCC implemented support for Objective-C. While also an alternative to #include, its function is to ensure that a header is only included in a project once. Although, this feature was later deprecated as it became agreed that it’s better that the header file is responsible for whether or not it is included multiple times. Hence, developers nowadays are instead expected to either use #ifndef guards (generally recommended) or #pragma once (not standard) - or soon, perhaps, modules!
In the case of our code, there aren’t multiple source files anyway, so #import is synonymous with #include:
#include "bits/stdc++.h"
auto main(register int(C), const char*(_)[]) noexcept -> int {
return operator<<(std::wclog, *(C ^= 074144, NULL[_] + 9))
<< (typeof(*_))new volatile const signed long long{C++}, !true;
}
bits/stdc++.h
https://stackoverflow.com/questions/25311011/how-does-include-bits-stdc-h-work-in-c
bits/stdc++.h is essentially a header that includes all the C and C++ headers, useful for quick testing, and especially useful for precompiled headers. Otherwise, though, it unsurprisingly slows down compilation, and it’s better to just include the independent headers that are actually used. In our case, all we’re doing is using std::wclog which comes from iostream, so we can just include that instead.
#include "iostream"
auto main(register int(C), const char*(_)[]) noexcept -> int {
return operator<<(std::wclog, *(C ^= 074144, NULL[_] + 9))
<< (typeof(*_))new volatile const signed long long{C++}, !true;
}
Moreover, we can replace the "" around iostream with the more typical <> as the only real difference in this case is expressing intention. This change signifies that iostream is an external header that is independent of our project:
#include <iostream>
auto main(register int(C), const char*(_)[]) noexcept -> int {
return operator<<(std::wclog, *(C ^= 074144, NULL[_] + 9))
<< (typeof(*_))new volatile const signed long long{C++}, !true;
}
Trailing return type
Trailing return types have been supported since C++11, which can make functions more readable in some cases via the syntax auto foo() -> T {}, reminiscent of Rust’s:
fn foo(x: u32) -> u32 { /* ... */ }
Generally-speaking, trailing return types have 3 main uses:
- Return type with
decltype(in C++11), beforedecltype(auto)was around (added in C++14):
template<typename A, typename B>
auto add(A a, B b) -> decltype(a + b);
- Lambda expressions (also introduced in C++11).
auto f = [](int x) -> double { return x; };
- Readability of more complex types.
template<std::integral T>
std::expected<BinaryView::Error, T> BinaryView::read(std::endian endian);
template<std::integral T>
auto BinaryView::read(std::endian endian)
-> std::expected<T, BinaryView::Error>;
In the case of main, the return type is just int, and so using a trailing return type is nothing but stylistic choice. Although I personally don’t enforce trailing return types in my code unless I’m using something verbose like std::expected, I do see why some programmers choose to use them in every function for consistency’s sake.
#include <iostream>
int main(register int(C), const char*(_)[]) noexcept {
return operator<<(std::wclog, *(C ^= 074144, NULL[_] + 9))
<< (typeof(*_))new volatile const signed long long{C++}, !true;
}
noexcept
https://en.cppreference.com/w/cpp/language/noexcept_spec.html
In short, noexcept as a specifier tells the compiler that a function will not attempt to propagate exceptions outwards - i.e., any exceptions that are propagated into the function are caught. This enables the compiler to make some optimisations as a result, but if the noexcept promise is broken, std::terminate is called instead, exiting the program.
So is there any point in tagging main with noexcept? Well, no, because main will exit if it has a propagating exception anyway. Therefore, it serves no real purpose here:
#include <iostream>
int main(register int(C), const char*(_)[]) {
return operator<<(std::wclog, *(C ^= 074144, NULL[_] + 9))
<< (typeof(*_))new volatile const signed long long{C++}, !true;
}
register
https://en.cppreference.com/w/cpp/language/storage_duration.html
The register keyword is an artefact of a time when compilers weren’t as intelligent as they are now; the first time I ever saw it used was in the DOOM codebase of all places.

What register does is signal to the compiler that a declared variable is going to be heavily used and should therefore be stored directly in a CPU register if possible, as registers are significantly faster to access than RAM.
However, the keyword was deprecated as of C++11 and outright removed in C++17, as compilers are allowed to ignore this hint if needed, and they can generally decide when a variable should be in a register more reliably than a human can. Therefore, we have no need for it here:
#include <iostream>
int main(int(C), const char*(_)[]) {
return operator<<(std::wclog, *(C ^= 074144, NULL[_] + 9))
<< (typeof(*_))new volatile const signed long long{C++}, !true;
}
Additionally, 64-bit systems primarily use the fast-call convention which puts the first 4 arguments of a function into CPU registers anyway, so using register on the 1st argument of a function like this really is pointless.
Parenthesised declarators
https://en.cppreference.com/w/cpp/language/declarations.html
C++ supports parenthesised declarators to help with disambiguation in certain contexts, although can also be used in other contexts too. For instance, the following code is valid C++:
int((((((((a))))))))=5;
More useful cases include:
- Function pointers
int *f(); // A function that returns int*
int (*f)(); // A pointer to a function that returns int
- Array pointers
int *a[23]; // An array of 23 int*'s
int (*a)[23]; // A pointer to an array of 23 int's
There’s also this funky case where the use of a constructor can be confused for a function declaration:
Foo bar(Baz()); // Could be a function that has a parameter for a function that returns Baz
Foo bar((Baz())); // Unambiguous - simply takes the result of the function call Baz() in Foo's constructor
But C++11 added curly-brace initialisation for this exact reason, which I for one use religiously:
Foo bar{Baz()};
In the context of our code, however, we don’t need this disambiguation. The first parameter of main is simply an int, and the second is a char* array (char**), so the parenthesis just hurt readability and should be removed:
#include <iostream>
int main(int C, const char* _[]) {
return operator<<(std::wclog, *(C ^= 074144, NULL[_] + 9))
<< (typeof(*_))new volatile const signed long long{C++}, !true;
}
Underscore identifier
Ignoring funky unicode stuff, C++ identfiers (such as variable names) can me made up of uppercase and lowercase Latin letters (A-Z and a-Z), underscores, and the digits 0-9 except for as the first character. There are also reserved identifiers, like with keywords and patterns like _Foo and __bar. However, a single underscore, _, rather than be reserved for wildcard syntax as seen in Haskell and Rust, manages to somehow slip through as a valid identifer. This means that _ can be used as a variable name.
Furthermore, C++ function type signatures are independent of the names given to the function’s parameters, hence we are able to change the typical argc to just C (in order to have C++ later in the code!) and argv to _. Changing these names back to normal, we get:
#include <iostream>
int main(int argc, const char* argv[]) {
return operator<<(std::wclog, *(argc ^= 074144, NULL[argv] + 9))
<< (typeof(*argv))new volatile const signed long long{argc++}, !true;
}
It is also worth noting that const can be used here without any issues as well. In fact, it is the first obfuscation so far that can actually be argued as idomatic C++, even if it is unusual! As such, I will choose leave it in.
Operator overloading
Anyone who knows C++ should remember the first time they learned how to print to the terminal, using the << operator as if constructing a conveyor belt for which to stream content into std::cout. Hopefully, with std::println slowly making its way into compilers, newcomers to C++ will never have to face this atrocity ever again. It is a textbook example of operator overloading gone wrong. At least, most would likely agree that overloading an operator to do something completely different from what it was originally intended to do is not a great idea, and we’d be better of defining new operators instead (>>= anyone?).
<< is originally the bitwise left shift operator, used for… well, shifting bits. It was unfortunate enough to have the ostream header overload it with its own custom behaviour.
That being said, a cool quirk of operator overloading, is that it necessitates some way to… overload operators, and C++ provides this by making it possible to define operators as functions, their symbols prefixed with operator (e.g., operator+ or operator<<).
This also means that when such an overload is defined, it can be called in this way too, hence the following code snippets are equivalent:
std::cout << "Hello, world!" << std::endl;
operator<<(std::cout, "Hello, world!").operator<<(std::endl);
With this mind, we can once again make our code significantly easier to read:
#include <iostream>
int main(int argc, const char* argv[]) {
return std::wclog << *(argc ^= 074144, NULL[argv] + 9)
<< (typeof(*argv))new volatile const signed long long{argc++}, !true;
}
std::wclog
But hold on, what is std::wclog? Shouldn’t it be std::cout that writes to standard output?
std::clog is similar to std::cerr in that they both write to standard error (stderr). However, unlike std::cerr, std::clog is buffered, meaning it is not flushed immediately, which is important where performance-critical conditions.
std::wclog is just the wide char version of this. Typically, a wide char is more than just 1 byte, but std::wcout and its variants all implicitly convert char* to wchar_t*. Therefore, both these code snippets have the same visual result when a wide char is 4 bytes:
static_assert(sizeof(wchar_t) == 4);
// Snippet 1
std::wcout << (wchar_t*)"b\0\0\0a\0\0\0z\0\0\0";
// Snippet 2
std::wcout << "baz";
Now, although it’s not immediately obvious that our code uses normal char* as input to std::wclog, we can see that (typeof(*argv)) is used as a cast (more on that later), which should evaluate to a (char*) cast. Therefore, it’s fairly safe to assume that we can just use std::cout instead, and we’ll also simplify the cast while we’re at it:
#include <iostream>
int main(int argc, const char* argv[]) {
return std::cout << *(argc ^= 074144, NULL[argv] + 9)
<< (char*)new volatile const signed long long{argc++}, !true;
}
Comma operator
https://en.cppreference.com/w/cpp/language/operator_other.html
One of my absolute favourite features of C is the comma operator, which I imagine many programmers aren’t aware even exists. What I find so fascinating about it is that it is technically useful - potentially really useful in some contexts - but is nevertheless generally bad to use.
Not to be confused with the use of commas in other C/C++ contexts (e.g. lists), the comma operator forms an expression in which the left-hand argument(s) are evaluated with their results discarded, while the evaluation of the right-most argument is what the expression returns, eerily similar to the >> operator in Haskell. Some seemingly useful applications of this include:
- Multiple varable mutation in index-based
forloops:
// Comma operator used ↓ here only!
for (int i = 0, j = 10; i <= j; ++i, --j)
std::cout << "i = " << i << " j = " << j << '\n';
- Makeshift lambda expressions (not really):
int a = (a = 5, a *= 3, a += 4, a %= 8, a ^= 23);
- Logging in return statements:
return LOG_ERROR("Some error."), -1;
In our code, we are incidentally making use of that last example, logging before returning !true. If we instead opt to write this out as two separate lines, we get something more conventional and readable:
#include <iostream>
int main(int argc, const char* argv[]) {
std::cout << *(argc ^= 074144, NULL[argv] + 9)
<< (char*)new volatile const signed long long{argc++};
return !true;
}
But we’re not done yet! There’s another use of the operator within the dereference we have going on. Extracting this out to yet another line, things should be starting to make more sense:
#include <iostream>
int main(int argc, const char* argv[]) {
argc ^= 074144;
std::cout << *(NULL[argv] + 9)
<< (char*)new volatile const signed long long{argc++};
return !true;
}
Implicit casting
https://en.cppreference.com/w/cpp/language/implicit_cast.html
Love it or hate it, C++ is notorious for implicit type conversion, so it’s pretty much expected that it’d turn up somewhere in this code - and sure enough, it’s easy to spot.
The function main has a return type of int, but we are attempting to return !true, so it must be that this bool expression is being implicitly converted to type int. In particular, !true == false, and false as an integer is simply 0. Therefore, we can write:
#include <iostream>
int main(int argc, const char* argv[]) {
argc ^= 074144;
std::cout << *(NULL[argv] + 9)
<< (char*)new volatile const signed long long{argc++};
return 0;
}
Array subscript commutativity
https://learn.microsoft.com/en-us/cpp/cpp/subscript-operator?view=msvc-170
The subscript operator, [], is defined such that a[b] == *(a + b). Because of how C pointer arithmeic works (more on that in a bit), this means that a[b] == b[a], and the expression NULL[argv] is equivalent to argv[NULL].
#include <iostream>
int main(int argc, const char* argv[]) {
argc ^= 074144;
std::cout << *(argv[NULL] + 9)
<< (char*)new volatile const signed long long{argc++};
return 0;
}
NULL
But what even is NULL? In C, it is typically defined as a null pointer, but this is implementation defined.
Importantly, it is allowed for NULL to be defined as the constant 0 or, as off C23, nullptr in order to remain compatible with C++. To avoid breaking this compatibility, it cannot be (void*)0, nor can it be an expression that evaluates to 0, like 10 * 2 - 20.
GCC defines NULL as its own magic keyword, __null, and is supposed to be a null pointer. Therefore, the GCC compiler generates the “converting NULL to non-pointer type” warning when attempting to index an array with it. As such, we’d best just use 0 to access the first element of an array:
#include <iostream>
int main(int argc, const char* argv[]) {
argc ^= 074144;
std::cout << *(argv[0] + 9)
<< (char*)new volatile const signed long long{argc++};
return 0;
}
Pointer arithmetic
https://www.learncpp.com/cpp-tutorial/pointer-arithmetic-and-subscripting/
As mentioned previously, the subscript operator expands to pointer arithmetic, such that a[b] == *(a + b).
However, consider the following:
int a[] = {0, 1, 2, 3, 4, 5, 6, 7};
int b = *(a + 4);
It’s important to note that a + 4 does not simply mean adding 4 to the address of a. Rather, it is adding 4 * sizeof(a[0]), which in this example evaluates to 4 * sizeof(int) == 4 * 4 == 16. Thus, *(a + 4) is equivalent to a[4], and gives the value 4 from the array.
Likewise, our code *(argv[0] + 9) is equivalent to argv[0][9]:
#include <iostream>
int main(int argc, const char* argv[]) {
argc ^= 074144;
std::cout << argv[0][9]
<< (char*)new volatile const signed long long{argc++};
return 0;
}
And since argv is a char** (i.e., an array of char arrays, i.e., an array of null-terminated strings), argv[0][9] is the 10th character of the 1st string in argv.
At this point, it’s useful to actually see what this string is, because Godbolt’s Compiler Explorer does in fact feed an argument to the program, and that is “./output.s”. Do some basic counting, and we can see that the 10th character in this string is indeed 's'. Let’s make all of this more clear in our code:
#include <iostream>
int main(int argc, const char* argv[]) {
argc ^= 074144;
const char* input = argv[0];
assert(input[9] == 's');
std::cout << input[9]
<< (char*)new volatile const signed long long{argc++};
return 0;
}
Octal
https://en.cppreference.com/w/cpp/language/integer_literal.html
Back in the 1970s, octal (base-8) encoding was all the rage.
Unfortunately, this meant that unlike binary literals which are prefixed with 0b or hexadecimal literals which are prefixed with 0x, octal literals are only prefixed with 0 in C (and by extension, C++).
So really, 074144 in our everyday base-10 is 30820, which we can replace here:
#include <iostream>
int main(int argc, const char* argv[]) {
argc ^= 30820;
const char* input = argv[0];
assert(input[9] == 's');
std::cout << input[9]
<< (char*)new volatile const signed long long{argc++};
return 0;
}
XOR
^ is C’s exclusive or bitwise operator, and essentially takes the bits of two values and compares their bits in pairs, individually setting the resultant bits to 1 if the pairs do not match, and 0 otherwise.
In our code, argc starts as 1 (because there is one argument given to the program) and then is XOR’d with 30820. If we compute 1 ^ 30820, we get 30821, just so happens to give the same result as if we had added them together.
#include <iostream>
int main(int argc, const char* argv[]) {
argc = 30821;
const char* input = argv[0];
assert(input[9] == 's');
std::cout << input[9]
<< (char*)new volatile const signed long long{argc++};
return 0;
}
Post-increment operator
https://en.cppreference.com/w/cpp/language/operator_incdec.html
Later in our code, we also see that argc is being incremented via the post-increment operator (argc++), the operator responsible for C++ being called what it is today.
However, although not immediately obvious, this operator doesn’t actually do anything in this context. This is because we are passing argc++ into the constructor of long long, meaning a new long long is constructed and argc is only incremented after the fact - unlike if ++argc was used, which would increment it before argc is accessed.
Therefore, since argc isn’t used used after this, the operation serves no purpose and can be removed.
#include <iostream>
int main(int argc, const char* argv[]) {
argc = 30821;
const char* input = argv[0];
assert(input[9] == 's');
std::cout << input[9]
<< (char*)new volatile const signed long long{argc};
return 0;
}
new
Now we’re very close to deciphering this completely!
It is usually advised to new C++ programmers to avoid using new as much as possible, especially for programmers coming from OOP languages like Java which use it extensively. This is because it allocates dynamic memory, unlike normal pointers which use automatic memory management. After all, dynamic memory is computationally expensive to work with!
However, a new expression can also serve another, extremely niche purpose: to get the address of some memory without needing to use the & operator, since new returns the address of the memory it allocates. And that’s exactly what’s happening here!
Therefore, since we would prefer not to use dynamic allocation anyway, let’s just use & to get the address of the existing variable argc rather than duplicate its data:
#include <iostream>
int main(int argc, const char* argv[]) {
argc = 30821;
const char* input = argv[0];
assert(input[9] == 's');
std::cout << input[9] << (char*)&argc;
return 0;
}
You’ll also notice that I’ve removed the volatile const signed long long, and that’s because it is just fluff, as will become evident in our final step…
String in disguise
Finally, we are down to the last layer of obfuscation, and this just uses a neat little trick that isn’t particularly special to C, but rather a quirk of how computers represent data in general.
First, it is important to understand that the char type is just the mapping of a byte-sized number ranging from 0-255 to what is typically an ASCII character. Therefore, a typical C string is just a sequence of these characters - an array of char values.
But what if we take a number that is bigger than a byte? Say, 30821. Well, assuming we are using little endian, 30821 as an int is represented in hexadecimal as 65 78 00 00 (note that each pair of digits is 1 byte). Therefore, an int can also be thought of as an array of bytes - 4 in total if we assume that sizeof(int) == 4.
So what happens if we take this number and treat it as a char array? Well, 0x65 == 'e' and 0x78 == 'x', so we get the string "ex".
However, it’s important to note that for a char array to be a valid C string, it must be null-terminated (i.e., ending with 0x00). As a result, we are able toget a string of maximum length 3 from a single 32-bit integer. "ex" is only of length 2, so it is indeed able to fit within these constraints, and a larger type like the 64-bit long long is unnecessary.
So, when we cast (char*)&argc, what we’re really doing is telling the compiler to process our integer argc as a string instead, and finally it becomes clear why our program outputs “sex”. Let’s remove this conversion and just make the value explicit:
#include <iostream>
int main(int argc, const char* argv[]) {
const char* input = argv[0];
assert(input[9] == 's');
std::cout << input[9] << "ex";
return 0;
}
And voilà, we have successfully picked apart the original obfuscated code to reveal what it is really doing!
Conclusion
So, it turns out that all this:
%:import "bits/stdc++.h"
auto main(register int(C), const char*(_)<::>) noexcept -> int {
return operator<<(std::wclog, *(C ^= 074144, NULL<:_:> + 9))
<< (typeof(*_))new volatile const signed long long<%C++%>, not true;
}
is really just an obfuscated way of doing this:
#import <iostream>
int main() {
std::cout << "sex"; // as in "sextet"
}
To whoever gave this a read, I hope it was as insightful to you as it was fun for me to put together. But do not be fooled! What I have covered here is but the tip of an iceberg that will lead you far into the depths of Hell if you dare to attempt traversing your way to its bottom.
Perhaps I am exaggerating, but if you consider the fact that the comma operator can be overloaded… am I really?